1
Concealing from whom? Threat modelling and risk as a relational concept
Nowadays, the field of encrypted messaging proposes a large variety of solutions for concealing, obfuscating and disguising private communications and other online activities, tailored to enable protection against specific ‘adversaries’. Security and privacy features worked into different protocols offer various degrees of protection and let users conceal different parts of their online identities. As a prelude to the more detailed analysis of how some of these systems are created, developed and used – which will be the objective of Chapters 2 to 4 – this chapter seeks to discuss how instruments such as ‘threat modelling’ and risk assessment are deployed during the development of encrypted messaging systems, in order to identify from whom a user needs to hide, or to analyse the possibility of an impending threat. It is not only important to know who to hide from, but also to evaluate the chances of actually ‘meeting’ this adversary. In fact, users perceive themselves, not as having a single identity, but rather as possessing a set of ‘profiles’ or ‘personas’, and every role may require particular patterns of digital self-care, served by specific sets of tools. These different personas imply a specific online behaviour pattern, thus creating what is called ‘security by compartmentalisation’. This chapter explores how, when applied to digital security, risk is a relational and socially defined concept, as it greatly depends on a user’s social graphs and communicative contexts.1
Creating and concealing an online presence
In response to the recent increasing variety of use-cases for encrypted secure messaging, a number of privacy-enhancing tools offer several different solutions to conceal private communications or other online exchanges. From the more popular centralised solutions such as Wire, Telegram, Signal and WhatsApp to less widely used decentralised platforms such as Ricochet or Briar – some of which will be the subject of the following chapters – and email clients supporting PGP encryption, these solutions are tailored to protect against specific ‘adversaries’. Security and privacy features worked into different protocols offer various degrees of protection and let users ‘hide’ different parts of their online identities.
The great variety of concealing devices that are being developed for our communicative tools is a response to the increasingly complex relationship between Internet users and the circulation of their personal data online. Indeed, our online traces are multi-layered and embedded in the material infrastructure of the Internet. Our identity can be disclosed not only by the content of our messages, but also by the unique identifiers of our hardware devices (such as MAC addresses), our IP addresses and other related metadata, thus contributing to the ‘turn to infrastructure’ in privacy and its governance (Musiani et al. 2016). This raises questions such as which of our multiple online identifiers can be considered as personal, which data should we hide, and from whom, and – to invoke David Pozen’s ‘mosaic theory’ (2005) – when does a combination of several items of a priori non-identifying information construct a degree of personalisation sufficient to de-anonymise a user?
Drawing upon previous work such as the anthropology of spam filters (Kockelman 2013), we understand cryptographic systems as sieves that separate items of information that have to be hidden from items that can be shown. Encryption algorithms appear as inverses or shadows of the information they sort. In fact, designing privacy-enhancing tools requires imagining the ‘worst of all possible worlds’, being constructed through various scenarios implying risk, uncertainty and flaws in security. Identification of a threat model serves as a way of agreeing upon an appropriate threshold of anonymity and confidentiality for a particular context of usage. Thus, different users may define in different ways who their adversary is, may disagree (or in any case, have to find grounds to agree) on which types of data should be concealed, and make a choice about which tools are more likely to give them the level of protection they need. Depending on different use-cases, from ‘nothing-to-hide’ low-risk situations, to high-risk scenarios in war zones or in authoritarian contexts, users, trainers and developers co-construct threat models and decide which data to conceal and on the ways in which to do it, which sometimes relies on a variety of arts de faire deployed by users to ‘hijack’ (Callon 1986) existing encryption tools and develop their own ways to conceal themselves.
To understand how threat models are constructed, it is useful to recall the interdisciplinary work that, in the last fifteen years, has explored the ‘collective’ dimension of privacy and the extent to which protecting it requires the interdependence of multiple factors and actors. For instance, Daniel Solove has described the ways in which the contours of online social representation are gradually identified as a result of the informational traces left behind by different interactions, dispersed across a variety of databases and networks (Solove 2006). These traces are at the core of states’ and corporations’ attempts to track and profile citizens and users, as well as central to activists’ strategies to expose corporate and state malfeasance. Successfully preserving one’s privacy in the connected world is thus about managing visibilities (Flyverbom et al. 2016). Along the same lines, emphasising the ways in which users can be active creators of their own privacy, Antonio Casilli has shown how the right to privacy has turned into a ‘collective negotiation’ whose main objective is to master one’s projection of self in social interactions with others (Casilli 2015). Paul Dourish and Ken Anderson nicely summarise the core message put forward by this approach to privacy and security when they suggest that these are ‘difficult concepts to manage from a technical perspective precisely because they are caught up in larger collective rhetorics and practices of risk, danger, secrecy, trust, morality, identity, and more. As an alternative, they argue that we should move ‘toward a holistic view of situated and collective information practice’ (Dourish and Anderson 2006).
Surveillance studies have also paid specific attention to the collective and relational dimensions of surveillance, privacy and security. Authors interested in exploring the concept of resistance have underlined the algorithmic and ‘rhizomatic’ nature of new surveillance practices and the responses needed to counter them (Martin et al. 2009); others show how a traditional conceptualisation of surveillance, involving an exclusive relationship between the surveillant and his object, does not properly take into account the ‘surveillant assemblages’ (including those that seek to respond to surveillance) that are currently on display in networked media, and are transforming the targets and the hierarchies of surveillance activities, while at the same time reconfiguring the notion of privacy (Haggerty and Erickson 2000).
Some contributions by scholars of online surveillance and privacy, while grounded in research that demonstrates the pervasiveness of digital surveillance and echoes the conceptualisation of surveillance as ‘assemblage’, are explicitly aimed at providing practical ‘guides’ for users. This is the case with Finn Brunton and Helen Nissenbaum’s Obfuscation, which aims to provide both a rationale and a set of tools aimed at the ‘deliberate use of ambiguous, confusing, or misleading information to interfere with surveillance and data collection projects’; these strategies may include noncompliance and sabotage (Brunton and Nissenbaum 2015). The work of Lex Gill and colleagues, with a particular focus on the Canadian context, also seeks to provide a ‘field guide’ to the debates on encryption and offer hands-on suggestions for ‘policymakers, legal professionals, academics, journalists, and advocates who are trying to navigate the complex implications of this technology’ (Gill et al. 2018). The increasing frequency of this type of contribution – the provision by scholars of hands-on guides in this field – is interesting to acknowledge in the context of this book. Such texts create hybrids that operate somewhere between scholarly contributions, on the one hand, and, on the other, practical guides meant to act as companions to the proliferation of tools and possible use-cases. Thus, such texts – and possibly, to some extent, the present book – contribute to concretely co-shaping users’ responses to surveillance and actions aimed at protecting privacy.
‘Know your enemy’: Threat modelling as a tool for trainers
In design studies and software engineering, threat modelling is considered an inherent part of the normal design cycle where ‘security needs’ are understood as yet another facet of the complex design process: ‘We must consider security needs throughout the design process, just as we do with performance, usability, localizability, serviceability, or any other facet’ (Torr 2005). When applied to the software development process, threat modelling is defined as a ‘formal process of identifying, documenting and mitigating security threats to a software system’ (Oladimeji et al. 2006). Threat modelling enables development teams to examine the application ‘through the eyes of a potential adversary’ in order to identify major security risks. However, threat modelling processes and techniques are also applied to human agents, in order to find security flaws in user behaviour patterns (both online and offline), identify sensitive information ‘to be protected’, determine potential adversaries, and evaluate their capacities and propose solutions for risk mitigation and protection.
The idea of threat modelling applied to users instead of informational systems is related to the difficulty – rather, the impossibility – of ‘hiding from everyone’. As the Electronic Frontier Foundation, a leading NGO in the digital security sphere, puts it:
It’s impossible to protect against every kind of trick or attacker, so you should concentrate on which people might want your data, what they might want from it, and how they might get it. Coming up with a set of possible attacks you plan to protect against is called threat modelling.2
Threat modelling is linked to another instrument called risk assessment. While threat modelling means identifying from whom a user needs to hide, risk assessment is a tool that trainers and digital security organisations use in order to analyse the chance of a threat being realised. It becomes important not only to know who to hide from, but also to evaluate the actual chances of coming face-to-face with one’s adversary. While risk has been described as a cultural ‘translation’ of danger (Douglas and Wildavsky 1982; Vaz and Bruno 2006), risk assessment is a ‘quantification of uncertainty’ (Hong 2017), that produces risk as something that can be ‘known, mitigated, increased and decreased, calculated’ (Porter 1995).
For the digital security trainers, we interviewed over the course of this research, threat modelling and risk assessment have become powerful instruments for narrowing down and structuring their training sessions. Several training sessions that we have observed in Ukraine and Russia used different threat modelling techniques. For example, the ‘Digital security for activists’ session that took place in Saint-Petersburg, Russia, on 10 April 2016, started with P., the trainer, offering the following introduction:
Before we start, we need to decide from whom we are protecting. First, the state. In just the last year 200 court cases have been opened because of online publications, comments and so on. Second, we should be protecting ourselves from corporations. It may be naive to say so, but it is clear that different corporations are accumulating information, and a lot of useful services that are given to us for free, however in exchange these companies are appropriating information about us. Third – there are other malicious agents who would like to get access to our online wallets or to hack us just for fun (translation from Russian by the authors).
This division between three categories of adversary was not just used rhetorically to introduce the training session: it was subsequently used throughout the three-hour workshop, in order to group various privacy-enhancing tools that people might need, around the three big categories of adversaries. Structuring training around a specific adversary means identifying not just the technical resources the adversary possesses, but also the extra-technical parameters – the legal context, for example.
Another way of structuring a training session was experimented with by Ukrainian trainers V. and M., both of whom specialised in high-risk users likely to face powerful, state-level adversaries, or maybe even physical threats. The training, held on 15 January 2017 in Kyiv, involved using a spreadsheet for both participants and trainers to complete (Figure 1.1).

Fig. 1.1 Digital security training observed in Kyiv, January 2017. The table includes the following columns (from left to right): Description of a person, its functions and activities, risks, ‘assets’ (devices, accounts, types of communications used), adversaries, threats (applied to the assets based on risks), possibility of a threat to happen, how to avoid risks (photograph by the authors).
The training was organised around a collaborative construction of several fictional profiles (for example: Anya, 25 years old, ecological activist; Oksana, 30 years old, journalist, etc.) and the identification of corresponding assets, adversaries and threats. In this way, trainers were focused not on enumerating existing privacy-enhancing tools, but on explaining a precise methodology of personalised threat modelling. For trainers, a user’s ability to analyse a very concrete situation and context is more important than their possessing sophisticated knowledge of multiple tools. Though some of the observed training sessions were nonetheless centred around demonstrations of particular tools, the majority of trainers are largely critical of tool-centred approaches and insist instead on tailored, threat-model-based forms of training:
Very often trainings turn into tool-trainings. But in our work tools are not our primary and even not secondary concerns. What’s primary is the evaluation of what participants need, what they already use. And only after we think of what we can suggest them to use, and again, without any hard recommendations ‘you need only this tool and that’s all’ (M., informational security trainer, Ukraine).
The digital security community is highly reflexive about its own training practices and the evaluation criteria used to assess secure messaging applications and mail clients. In recent years, the transition from a tool-centred approach to a user-centred one has been something of a paradigm shift among trainers and experts, where the user’s capacities to evaluate their own threat model are seen as increasingly crucial. As the famous EFF guide ‘Surveillance Self-Defense’ puts it,
Trying to protect all your data from everyone all the time is impractical and exhausting. But, do not fear! Security is a process, and through thoughtful planning, you can assess what’s right for you. Security isn’t about the tools you use or the software you download. It begins with understanding the unique threats you face and how you can counter those threats.3
This ‘tailored approach’ to threat models during security training sessions is also important because developers in the secure messaging field are currently discussing a number of unsolved cryptography problems, such as metadata storage, the vulnerabilities of centralised infrastructures, the usage of telephone numbers as identifiers and so on. In the absence of the ‘perfect tool’ in all these respects, trainers recommend patchworks of different tools and operational security practices (‘physical security’) that aim to minimise the drawbacks of existing tools and offer different features, from encryption ‘in transit’ to encryption ‘at rest’, metadata obfuscation, and so on. Threat modelling is a practice that helps to fix, and in some ways compensate for, some of these unsolved technical problems.
It is also important to note that, for a specific threat model, extra-cryptographic factors such as a particular tool having a low learning curve before it can be used, peer pressure or network effect (first-time users joining a tool because a critical mass of individuals already uses it) may be more important than the technical efficiency of a cryptographic protocol. Thus, a trainer in Ukraine would – seemingly counter-intuitively but, from their standpoint, ultimately logically – often advise their high-risk users to use WhatsApp and Gmail instead of Signal or a PGP-encrypted form of email, as ‘everyone already uses it and knows how it works’. In other words, the adoption of these tools will happen quicker and result in fewer mistakes. Thus, time and learning curve become additional factors affecting the recommendation of a specific tool.
‘Nothing to hide’ or ‘tinfoil hat freaks’? A continuum of risk levels
Away from trainers and digital security experts, users develop their own methods to evaluate their risks, and invent specific ad hoc practices of digital self-defence. However, even after the Snowden revelations, a significant proportion of European citizens share the idea that they have ‘nothing to hide’, sometimes considering the mere fact of concealing online traces as a potential indication of criminal activity. A recent study has revealed a certain state of public apathy: ‘though online users are concerned and feel unease about the mass collection of their personal data, the lack of understanding as to how such data is collected as well as a sense of powerlessness leads to the public’s resignation and apathy’ (Hintz and Dencik 2017).
The ‘nothing to hide’ argument has, famously, been widely criticised by the security community, resulting in the production of a variety of cultural content and online tutorials aimed at increasing the awareness of the general public about digital security.4These contributions fuel the ongoing debate about the thin line separating both targeted surveillance from mass surveillance and high-risk from low-risk users. The demarcation between hiding from governments and hiding from corporations is also increasingly blurred, with the image of the ‘adversary’ becoming much more complex and hybrid (Musiani 2013).
While the vast majority of user studies in usable security – the field of study that evaluates the usability of digital security – have been conducted with subjects from the ‘general population’ (in fact, usually, university students), our research provides slightly different results regarding users’ awareness of and concerns about privacy. We classified our interviewed population against two axes: individuals’ knowledge about technologies and their risk situation. This resulted in four groups that we will examine in turn in the remainder of this chapter – although, as we will further explore later, while we found this distinction operationally useful, it also had its limits.
For profiles with a low-level risk situation but possessing a high degree of technical knowledge, the awareness of privacy and security related risks was very high; however, the generally adopted user behaviour was not holistically secure: a large number of tech developers or trainers were using unencrypted email and text messaging applications. For example, despite recent usability research showing that Telegram was suffering from a number of important usability and security problems (Abu-Salma et al. 2017a), with encryption for group chat being very basic, Pirate Party activists – themselves software developers, system administrators and/or hosting providers – use Telegram on a daily basis (for example, the group of Pirate Party Russia on Telegram counts 469 users as of 24 November 2019). However, other tactics of self-defence are used, such as self-censorship (avoiding talking about specific topics) and pseudonymisation (avoiding real profile photos and usernames).
Surprisingly, there is no strict correlation, at least in our interviews, between users’ threat models, level of technical knowledge, the security features of a tool – such as key length or key generation algorithm – and the dynamics of tool adoption. Instead, other extra-cryptographic and extra-security features can become arguments for the adoption of a specific tool. In the case of Telegram, it is interesting to observe how the actual cryptographic protocol and security and privacy properties lose their importance for users, compared to the features of the interface and to the reputation of the app’s creator. The trust in Telegram, according to our interviews, is not located in the technology, but in the person using the technology and their political position:
User1: ‘Maybe you should not discuss that over Telegram?’
User2: ‘Why not? Pashka Durov will never give away any of our data, he does not care about Russian police’ (from online discussion in a group chat ‘Soprotivlenie’ [Resistance], posted on 11 June 2017; translation from Russian by the authors).
Within high-risk and low-knowledge populations, however, the awareness of risks regarding privacy issues (such as the necessity of using privacy-preserving browser plug-ins) was not absolute, with behaviour related to email and messaging estimated as being more important. Even if these users could not always clearly describe possible attack vectors, they had a highly multi-faceted and complex image of who their adversary was. This was clearly expressed in the drawings collected during interviews and observed workshops, which respondents drew when asked by us to illustrate who or what they considered to be their adversary (Figure 1.2).
‘Low-knowledge, high-risk’ users, for their part, deploy specific, often unique and personal, methods to protect their communications and information, resulting in an assemblage of different tools and practices, both in their offline (social engineering, operational security or ‘opsec’) and online behaviour (Figure 1.3).
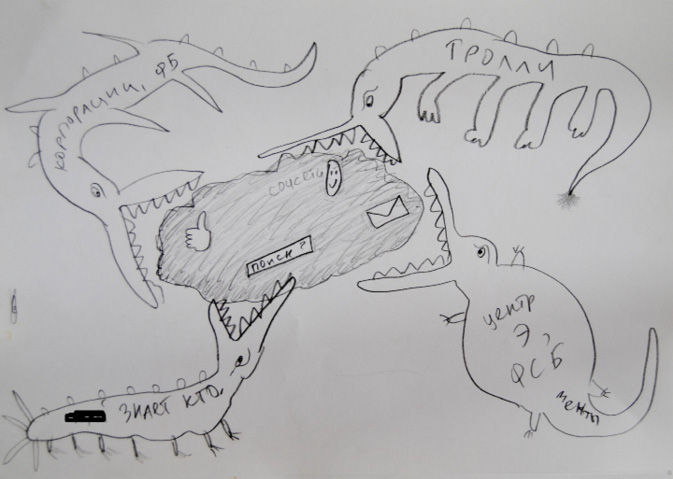
Fig. 1.2 User representation of ‘insecure communications’. Drawing collected during a digital security workshop in Saint-Petersburg, April 2017. By a female activist of a feminist collective. The ‘crocodiles’ are labelled (from left top clockwise): ‘Corporations, Facebook’; ‘Trolls’; ‘Center against extremism, FSB, police’; ‘Who the f**k knows’. On the cloud: ‘Search’; ‘Social networks’.
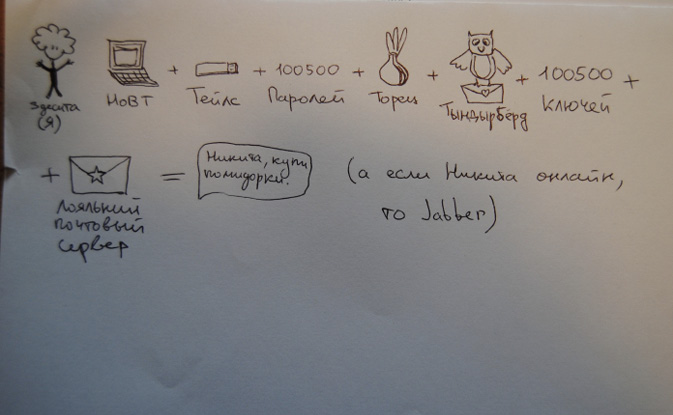
Fig. 1.3 User representation of ‘secure communications’. Drawing collected during a digital security workshop in Saint-Petersburg, April 2017. Female, antifascist activist. From the left: ‘Me: laptop + Tails + 100500 passwords + Tor + Thunderbird + 100500 keys + trusted email provider = message “Nikita, could you buy some tomatoes please?” (And if Nikita is online, then Jabber)’
For instance, high-risk users in Russia and Ukraine – namely left-wing activists who face police threats and targeted surveillance – are widely using the so-called ‘one-time secrets’, special web-based pastebins or pads that claim to destroy messages once read.5 These users describe the main threat they face as being the seizure of their devices. Thus, they suggest, a self-destroying link is the most secure way to communicate, even though the links to these locations are often sent via unsecured channels, such as Facebook Messenger. The flip side of these practices is that applications that are a priori more specifically targeted to activists become infrequent choices for these high-risk users.
Security by compartmentalisation and ‘relational’ risk
As these examples show, the multitude of messaging apps echoes the variety of user behaviour and risk assessment practices. In fact, users perceive themselves as having a plurality of identities, each of which may require specific digital self-care practices and sets of tools. This creates what we call ‘security by compartmentalisation’.
Users select different messaging apps for different groups of contacts, according to the perceived level of risk. Even some of our high-risk interviewees report that they use WhatsApp or Facebook Messenger for work and family relations, while preferring PGP-encrypted email, Signal or Privnote for activist-related contacts. Some prefer to move all the communications to a single application, but report having a hard time convincing relatives to change their online behaviour (the so-called ‘digital migration problem’) or face compatibility problems (for example, older phones cannot run Signal).
As a consequence, when applied to digital security, risk is a relational concept, as it greatly depends on the user’s social graphs and contexts of communication. A high-risk user from Ukraine, involved in a collective for the support of political prisoners, explains:
My risk is always connected to the risk of other people. I do not want to use my mobile phone to connect to my activist account, as it will be possible to connect the two. And even if I think that I have not done anything, other people have reasons to hide themselves. And finally… I never know when someone comes after me. Predicting future is not wise. Khodorkovsky just before his arrest also said that no one was interested in him.
In this sense, even though using axes to categorise users can serve practical ends – making it easier, for example, to apply statistical treatments to our data, something that the technologists in the NEXTLEAP team very much appreciated, which resulted in a few collaborative papers – the difference between low-risk and high-risk users is actually highly context-dependent, and always shifting: a low-risk person in contact with high-risk ones has to increase their level of security and may themself become high risk. As a user from Austria, a festival organiser self-identifying as a low-risk person, puts it:
I work on a festival which is all about generating outreach. And I adapt to the people I invite or strategize projects with. So the risk of my communication is related to the risk taken by the people I am talking to. So for example with [X], [Y]6 or others I always encrypt everything of course and I also always check if a guest I am inviting has a public key on a keyserver so I start communication encrypted […] Enemy? Lots of my guest speakers have serious enemies; so I again adapt to that.
This ‘compartmentalisation’ approach to security also results in some hardware-based user bricolages or tinkering, ranging from the more popular practice of ‘dual-booting’ (combining an ‘activist’ and a ‘normal’ operating system on the same machine), to more sophisticated hiding places or concealed operating systems. These user behaviours and user-driven practices of security by compartmentalisation have been recently incorporated by design in a project named Qubes. This is an operational system based on a multitude of virtual machines creating isolated working environments that let users coordinate and manage different ‘parts’ of their online identities with different needs and security requirements.
However, risks and threat models also evolve over time. Not only are these dependent on users’ relational networks, but also on the supposed reactions and behaviours of the adversary. Thus, for this high-risk and high-knowledge user from Greece, it is important to constantly reinvent their everyday security practices:
According to the act or what I do I have a specific OPSEC. I remember the main steps by heart, though I don’t use the same practices every time as once used a specific methodology then it’s burned. Depending on the place I try to masquerade to the common practices of this area rather than blindly improvise. The adversary is always learning from me and from trusted people or friends that are not careful enough.
If the distinction between high risk and low risk needs to be taken with a grain of salt, so too do the definitions of sensitive and insensitive data. Religion, morality and gender become important parameters in influencing the definition of what ‘sensitive information’ is. Our interviews with Middle Eastern users, for example, show that one of the most important adversaries from whom Muslim women have to hide is their own partner or family member. As one of our interviewees, a twenty-seven-year-old Iranian woman, explains, photos of a non-religious wedding can become as sensitive as an instance of political critique, and can present significant levels of risk to the person sharing the photos. It is not, therefore, the type of information itself that defines the category of ‘high risk’, but the user’s broader context: threat models and risk levels thus can be gender and culture dependent.
‘If you use that tool, you have something to hide’: Paradoxes of the mass adoption of encryption
According to our fieldwork, open-source and licensing choices are covered less in high-risk training sessions, as high-risk users do not always associate open source with security. Open source was perceived as a less important criterion in the context of an immediate physical threat: if a proprietary but ‘efficient’ and ‘easy to explain’ solution exists, trainers will give it priority. For example, in Ukraine, WhatsApp is the most recommended application, because it is considered easy to install. Trainers consider WhatsApp’s proprietary license and collaboration with Facebook (notably in relation to metadata sharing) as less important than users’ perceptions around security. The primary task in high-risk contexts with low-knowledge users is to help them quickly abandon unencrypted tools, as well as tools whose creators may be collaborating with their adversaries.
Since WhatsApp adopted end-to-end encryption, we usually do not spend that much time on instant messaging encryption [during trainings] and recommend to stay with WhatsApp if people already use it. So they can still communicate with all of their friends, and also… it looks familiar, and it does not shock them. And people say [during trainings] if they use WhatsApp it’s less suspicious than if they use a special app for activists (I., female informational security trainer, Ukraine).
This quote raises an important concern addressed by a number of our user interviewees and observed during both cryptoparties and informational security trainings: does the very fact of using an activist-targeted app constitute a threat in itself? This refers to Ethan Zuckerman’s (2008) famous ‘Cute Cat Theory of Digital Activism’, according to which it is safer and easier for activists to use the same mainstream platforms as those used for sharing ‘lolcats’ pictures, whereas using a tool marked as ‘activist’ may put users under targeted (and thus, easier and cheaper) surveillance.
This concern reveals a shared (but often underexplored) anxiety among users about specific kinds of metadata (even though this particular term is not always used explicitly), e.g. data about their installation of particular apps. In interviews, we were often confronted by an extensive critique of all the existing tools by both informational security trainers and non-technical users. This echoes the findings of another recent usability study of end-to-end encryption tools, which concluded that ‘most participants did not believe secure tools could offer protection against powerful or knowledgeable adversaries’ (Abu-Salma et al. 2017b: 2). Many users mentioned as a reason for not adopting encryption the fact that their social graphs and ‘activist’ lifestyle would be exposed to adversaries by using specific tools. A Russian user also mentioned the opposite effect – using an activist-targeted tool as means of ‘earning trust’ – recounting the story of an undercover police officer who used a @riseup.net email account as a way of penetrating a student movement mailing list during the 2011–12 mass protests.
The quintessence of this ‘tool-scepticism’ can be illustrated with a drawing (Figure 1.4) authored by one of our respondents – a European high-risk war correspondent working in the Middle East – when asked to draw a representation of his adversary.
The adoption of encryption by mainstream messaging applications (as opposed to applications designed more specifically for activists) leads to a peculiar effect that one of our respondents summarised as ‘fish in the sea’ (used in the sense of being ‘one among many similar entities’ in a wide-open space that offers mutual protection via mutual concealment):
Imagine if I have nothing to hide, but I still use an end-to-end encrypted app, then people who need to hide themselves… like whistleblowers for example… it will be easier for them, say, to disappear in this big flow of cat photos or love messages. So I feel like I am helping someone when I use encryption all the time for all of my communications (Female, low-risk user, tech-journalist, Austria).
An interesting phenomenon of ‘shared responsibility’ arises from this mass adoption of encryption: the more users opt for end-to-end encryption tools, the more secure it becomes for everyone to use these tools, but specifically for those users whose life and freedom depend on them. As we will see in the following chapters, while in the mass adoption of distributed or peer-to-peer applications there is a real technical correlation between the number of users and the level of privacy protection, for centralised applications (like Signal and WhatsApp) or for email encryption, the consequences of mass adoption are often described as increasing the difficulty, human and technical, for the adversary to achieve its surveillance objectives:
The more people use encryption, the more expensive it will be for the governments to read everything. It’s not about reaching 100% security… This simply does not exist! It’s about making them waste their time and money to decrypt our stuff and in the end they are reading something like ‘Let’s go eat pizza tonight’… (male, informational security trainer, Ukraine)
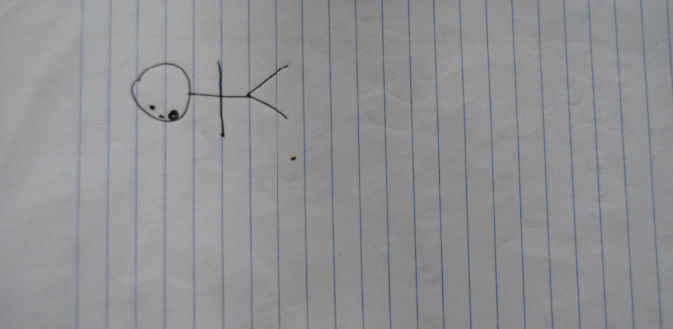
Fig. 1.4 Drawing collected during the interview on February 16, 2017. The user commented on the drawing as follows: ‘In the case of a truly secure communication I say something, but no one knows what I said and to whom […] I could have just given you a blank sheet of paper, it would have meant that no traces of a communication act are visible. But as soon as you asked me to draw you something…’ (C, male, journalist, high risk).
Even though the collaboration of Signal’s head developer, Moxie Marlinspike, with WhatsApp and Facebook was controversial and subject to critiques within a number of tech-savvy circles – in particular in the F/OSS (Free and Open-Source Software) communities – mass adoption of end-to-end encryption had an important impact on Internet governance. With applications such as WhatsApp bringing strong cryptography into the mainstream, the thesis of ‘encryption as a human right’ and the demand for ‘equal access to encryption’ have become more widespread. Among recent initiatives, a 2017 letter signed by 65 privacy-focused NGOs (including Privacy Now, EFF and Article 19) and addressed to the UN, demanded the decriminalisation of users of privacy-enhancing technologies and digital security trainers (see IFEX, 2017). Two years earlier, privacy and the right to conceal were presented by the United Nations Special Rapporteur on Human Rights as a core component of freedom of opinion and expression:
Discussions of encryption and anonymity have all too often focused only on their potential use for criminal purposes in times of terrorism. But emergency situations do not relieve States of the obligation to ensure respect for international human rights law […] General debate should highlight the protection that encryption and anonymity provide, especially to the groups most at risk of unlawful interferences (Kaye 2015).
In our interviews, developers and information security trainers underlined the urgency of finding a reliable solution to the problem of metadata collection. As we have already implied, this is a key area where debates around encryption become relevant. Metadata are data that describe or provide information about other data, such as social media discussions, email exchanges or online transactions. Devices and systems that are connected to the Internet (or support its operation), including messaging and other online communication systems, collect this ‘information about information’ that, when aggregated, can account for a user’s daily Internet activities, but also for real life activities and activities of other users. The collection of metadata is, or can be, especially problematic because it happens in the background and for a variety of purposes, and users can usually gain access to a mere fraction of the metadata collected about them. Controversies around metadata collection are numerous, including the presence of informed consent, the level of clarity concerning use or sharing, the existence of retention policies (documents stipulating how long an entity will store metadata) and the legal possibility of bulk or warrantless collection, in particular by governmental agencies (Piscitello 2016). Ultimately, developers and trainers appear to share a consensus that there is currently no solution in the field of end-to-end encrypted instant messaging apps that offers good metadata protection. Developers and trainers associate the leaking of metadata with centralisation:
Metadata connects you weirdly with other people, and there’s more sense in the metadata than in the data itself for technological reasons […] No one from the messaging apps is trying to solve that. Instead they suggest to sync your address books so they know exactly who you’re talking to even though you trust them to somehow make it into hashes or whatever. That’s the issue we are not solving with the apps, we make it worse. We now have centralised servers that become honeypots, and it’s not about the data, it’s about the metadata (Peter S., Heml.is).
‘Actually, in Google we trust’: Questioning the privacy-security dichotomy
When we first attempted to interpret our fieldwork, our hypothesis was that very distinct threat models could be associated with distinct types of users, grouped according to their risk status – ‘high’ or ‘low’. As already noted, this hypothesis was operationally useful, especially for our joint work with computer scientists more familiar with usability studies. However, our fieldwork showed the limits of this opposition, demonstrating the relativity of two binary visions: users could be categorised not only as high risk vs low risk, but also according to their concern about privacy vs security. These two concerns, and the defensive practices they give rise to, are in fact interpenetrating, as the remainder of this section will further demonstrate.
Indeed, among our interviewees, citizens of supposedly ‘low-risk’ countries (Western countries led by long-term democratic regimes) were more concerned with privacy-related issues, while individuals ‘at high risk’ (i.e. belonging to particular socio-demographic groups that placed them in the spotlight of authoritarian regimes) focused on urgent needs and life-and-death situations, often adopting technical solutions that are easier to install and use, even if they do not, in fact, provide strong levels of privacy protection (WhatsApp, for example). This difference can be exemplified by the different attitudes towards tech giants, such as Google, Apple, Facebook, Amazon and Microsoft. Criticism of these companies mostly comes from Western users who have a high degree of knowledge about information technology and its socio-economy. Several ‘high-risk’ users, by contrast, shared the idea that centralised and quasi-monopolistic services like Gmail, for example, offer a better security-usability ratio. In a context of risk and urgency, there tends to be a compromise between user-friendliness and security, while technically experienced low-risk users often focus more on developing genuinely complex and multi-layered privacy and security preserving toolkits.
However, some of the criticisms of the practices of tech giants that have originated within the F/OSS community have touched larger, non-technical populations in high-risk countries. An example is the controversy about Signal’s dependence upon Google Play and Google Services,7 which originated within free software circles with the launch – and subsequent rapid shutdown – of the project LibreSignal.8 Signal’s dependence upon Google became a problem for a specific privacy-aware and tech-savvy user community, who opt for decentralised alternatives to the communication tools provided by Net giants. In this context, the choice of a ‘Google-free’ messenger can also be perceived as a ‘lifestyle’ choice. This choice often coexists with alternative choices of hardware (e.g. a Linux phone, a Fair Phone, Copperhead OS, or other privacy enhancing tools). As one tech-savvy user put it, ‘If I don’t like mainstream in media, if I don’t like mainstream in music – why would I like mainstream on my computer?’ [Daniel, mail service provider, festival organiser].
However, according to our interviews, Signal’s dependencies on Google Play had an important impact not only on tech-savvy users from a priori low-risk environments, but also on users in problematic settings and with little technical knowledge. For example, in Syria, the country-wide blocking of Google Play meant that low-knowledge users no longer had comfortable and immediate access to the Signal app, yet they lacked the competencies to look for alternative routes to acquire it. Technical decisions made by developers of privacy-enhancing technologies – such as dependencies on third-party libraries and their licensing and protocol choices – are not only a preference or lifestyle issue for users but may also impact their security in life-and-death contexts.
Users in ‘high-risk’ type settings also mentioned as important for their threat models the issue of decentralised networks, once considered an overwhelmingly ‘high-tech, low-risk’ concern. For example, our recent exchanges with Russian and Ukrainian left-wing activists revealed a growing desire among these populations to run their own file storage and decentralised communication infrastructures.
Conclusions: Risk is relational, threat modelling is crucial
By providing a number of examples related to contexts of use, users’ perceived needs and selection of possibly appropriate tools, this chapter has shown that in the field of online communications, and more particularly secure messaging, risk is relational, and threat modelling is crucial for choosing the right tool to protect one’s communications. For example, if a user’s primary objective is to conceal from one’s own government, this objective is inextricably entangled with changes in consumer habits and migrating from closed-source platforms with business models based on user data. In this context, the ‘adversary’ resembles a constantly evolving, fluid network connecting with both private and institutional infrastructures, rather than a single entity with well-defined capacities and a predetermined set of surveillance and attack techniques and tools.
Trainers and digital security organisations are shifting towards a user-centred approach and user-tailored training sessions. At the same time, they increasingly face the challenge of communicating to their trainees that privacy-preserving and privacy-enhancing tools do not guarantee, in and by themselves, absolute security. Unsolved cryptographic challenges, such as how to build usable metadata-preserving solutions, are somehow ‘compensated for’ by a patchwork of operational security techniques and combination of tools that users invent and constantly modify. Thus, the identification of ‘who we must conceal from’ – threat modelling and risk assessment – is a constantly changing process that depends upon a large set of often non-technical or non-cryptographic parameters, such as a user’s social graph, gender, religious or ethical norms, profession, geopolitical situation/the political regime, or the reputation and charisma of app creators. Indeed, encrypted communication is the product of, and sometimes the catalyst for changing, a vast network including institutions (or actors positioning themselves in opposition or resistance to them) and of course, myriad infrastructures and technical devices in which concepts such as security and privacy are embedded (see our previous discussion about ‘doing Internet governance’ in the introduction).
The very distinction between high risk and low risk, while useful operationally for the researcher as a practical methodological tool in order to build a diverse sample of users for interviews, shows its limits, mainly due to the ‘relational’ nature of risk we have introduced in this chapter. If a low-risk user has at least one high-risk user in her social graph, she may adopt a higher level of protection and even install a specific tool for communicating with this contact – and inversely, in specific sociopolitical contexts, what is usually understood as low-risk/non-sensitive data may in fact place its owners in higher risk categories. Indeed, if designing privacy-enhancing tools requires imagining the ‘worst of all possible worlds’, this may well be the world of an individual among our contacts: the person who is most in need of concealing. The following chapters explore how developers seeking to respond to the ongoing turn to ‘mass encryption’ take this into account, as they explore different architectural configurations for encrypted secure messaging tools and cope with their constraints and opportunities.
Notes
1 An earlier version of this chapter was published as Ermoshina, K. and F. Musiani, ‘Hiding from Whom? Threat Models and In-the-Making Encryption Technologies’, Intermédialités: Histoire et théorie des arts, des lettres et des techniques, 32 (2019), special issue Cacher/Concealing. It was also presented and discussed at the annual conference of the International Association for Media and Communication Research in Eugene, Oregon, 7–11 July 2018. We are grateful to the French Privacy and Data Protection Commission (CNIL) and Inria for selecting this work as a runner-up to the 2019 CNIL-Inria Privacy Protection Prize.
3 See, https://ssd.eff.org/en/playlist/academic-researcher#assessing-your-risks; we will analyse in Chapter 6 how this shift entails a change of methodology used to rank, evaluate and recommend secure communication tools.
4 Among recent initiatives, the documentary Nothing to Hide: http://www.allocine.fr/video/player_gen_cmedia=19571391&cfilm=253027.htm.
5 The most popular services are One Time Secret (https://onetimesecret.com) and Privnote (https://privnote.com).
6 Mentioning two important and well-known tech and human rights activists.
8 https://github.com/LibreSignal/LibreSignal; see Chapter 3.